Sharded Distributed Key-Value Store with OmniPaxos Consensus(Go)
Introduction
This project focuses on designing, implementing, and benchmarking a distributed, fault-tolerant Sharded Key/Value Store using the OmniPaxos consensus protocol. The system partitions keys across multiple replica groups to improve throughput and support scalability. The project consists of two main components:
- Shard Controller: Manages shard assignments to replica groups and handles configuration changes.
- Shard Key/Value Servers: Stores and manages shards, ensuring linearizable operations across configurations.
Additionally, performance benchmarking was conducted to analyze latency and throughput under various workloads using CloudLab’s infrastructure.
System Design Overview
OmniPaxos Overview
OmniPaxos is a consensus protocol that ensures fault-tolerant and consistent state replication across distributed systems. In this project, OmniPaxos was employed to achieve the following:
- Fault Tolerance: Allows the system to tolerate failures of a minority of nodes within a replica group or the shard controller.
- Log Replication: Ensures all replicas in a group apply operations in the same order, maintaining linearizability.
- Dynamic Reconfiguration: Handles configuration changes, such as shard migrations, while ensuring a consistent system state.
Key components of OmniPaxos in this project:
- Consensus Module: Replicates both client operations (e.g., Put/Get/Append) and configuration changes across replica groups.
- Apply Channel: Delivers ordered log entries to the state machine, ensuring consistency during shard migrations and reconfigurations.
- Fault Recovery: Recovers from node failures by replaying logs and synchronizing missing data between nodes.
OmniPaxos’ deterministic logging mechanism was crucial for coordinating shard migrations and ensuring a single source of truth for shard ownership.
Shard Controller
The shard controller is responsible for managing the mapping of shards to replica groups. It supports the following RPC operations:
- Join: Add a new replica group to the system.
- Leave: Remove a replica group from the system.
- Move: Assign a specific shard to a replica group.
- Query: Retrieve the current or specific past configurations.
The shard controller ensures fault-tolerance using OmniPaxos and dynamically balances shards to minimize migration overhead during configuration changes.
Shard Key/Value Servers
Each replica group operates as a Paxos-backed storage system, serving a subset of shards. Key features include:
- Linearizability: Ensures that all operations appear in a single, globally consistent order.
- Shard Migration: During reconfiguration, servers transfer shard data between groups via RPC.
- Duplicate Request Handling: Ensures at-most-once semantics for client operations.
System Workflow Diagram
Below is an overview of the Sharded Key/Value Store system workflow:
This diagram illustrates the interaction between clients, the shard controller, and shard key/value servers. It also highlights the role of OmniPaxos in ensuring fault tolerance and consistency.
Performance Benchmarking
Setup
Benchmarks were conducted on CloudLab using the following configuration:
- Nodes: Single
r320instance with Ubuntu 22.04 OS. - Sharding: Keys distributed across three benchmarks, simulating varying workloads.
- Metrics:
- Latency: Measured in nanoseconds.
- Throughput: Measured as operations per second.
Benchmarking Procedure
The benchmarking process involved running three workloads:
- Benchmark A: All shards being concentrated in a single group.
- Benchmark B: Shards are evenly distributed across two groups.
- Benchmark C: While two groups are used, most requests are handled by one group.
Metrics were instrumented during these benchmarks, and results were visualized using Matplotlib.
Results and Analysis
Latency Analysis
The Cumulative Distribution Function (CDF) of latency for the three benchmarks is shown below:
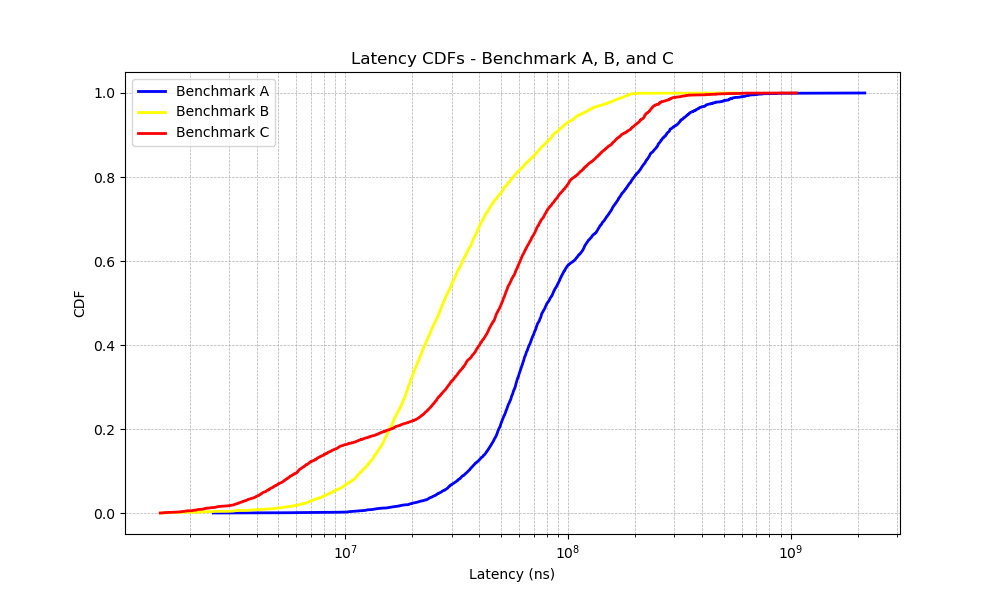
Observations:
- Benchmark A (Blue): Exhibits the highest latency due to all shards being concentrated in a single group. The single server handling all requests results in high server load and poor performance.
- Benchmark B (Yellow): Shows the lowest latency as shards are evenly distributed across two groups, balancing the load and reducing bottlenecks.
- Benchmark C (Red): Latency falls between A and B. While two groups are used, most requests are handled by one group, with partial load balancing occurring.
Throughput Analysis
The average throughput for each benchmark is summarized below:
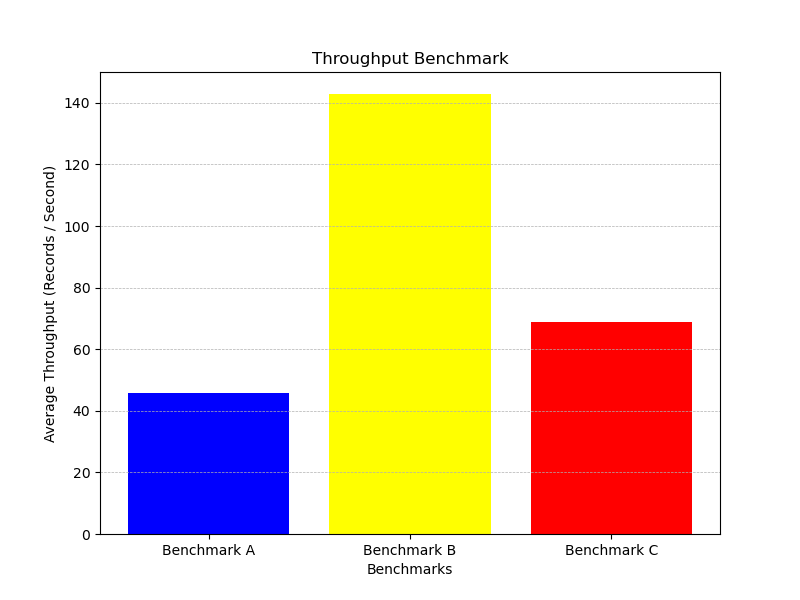
Observations:
- Benchmark A: All shards are joined to a single group, and one server handles all requests, creating a bottleneck. This results in the slowest throughput due to high server load.
- Benchmark B: Shards are evenly split between two groups, resulting in the fastest throughput due to balanced load and reduced bottlenecks.
- Benchmark C: Two groups are also used, but most requests are handled by one group, with some routed to the other. Throughput is intermediate, combining some load concentration and partial balancing.
Summary of Benchmarks
- Benchmark A: Slowest due to server overload caused by all shards being handled by a single server.
- Benchmark B: Fastest with balanced load distribution across two groups.
- Benchmark C: Intermediate performance, balancing partial load concentration and reduced bottlenecks.